3 Lessons from the paper "Attention Is All You Need" as a Beginner

With the recent surge of news about image, or even art, generating AI, I'm sure I'm not the only one who was interested in how this works under the hood. Most of these results are achieved by so-called "transformer" models and even though it seems like they are coming out just now with the huge media coverage, the idea of these actually started over 5 years ago.
I wanted to get a glimpse into the transformer-world. So in my personal September study goals I decided to read the paper that kicked off the developments in the area of transformers that we have seen in the years since its publications in 2017: "Attention Is All You Need" by Vaswani et al., working for Google at the time. I knew that I wouldn't understand the whole paper (research papers can be quite overwhelming for people not actively researching in the field), but my goal was to find out where my knowledge gaps might be, so I could start filling them.
What does it mean to be a "beginner" in this context?
I studied mathematics and computer science, and in my master's thesis I focused on theoretical properties of stochastic gradient descent for deep learning. So I do have a good understanding of the general theory of machine learning, but I have limited experience with language translation models or deep learning architectures that process sequences, so I'd call myself a "beginner" in the area of transformers.
If you are completely new to machine learning, but want to learn how it works and possibly apply it yourself, this post about a scientific research article, might be confusing. In this case, I would redirect you to a beginner-oriented course like Andrew Ng's Machine Learning on Coursera, followed by a course like the Deep Learning Specialization for the basics.
Lesson 1: Previous architectures not only included Recurrent Neural Networks, but also Convolutional Networks
The attention-based transformer architectures didn't just replace recurrent neural networks. Another type of architecture that was used for sequence modeling were convolutional neural networks. This surprised me quite a bit.
During my studies I've learned about recurrent network architectures, like LSTMs, in the context of image descriptions or text generation in a specific style. However, I'd only encountered convolutional networks in the context of processing images. When looking at images, the advantage of a convolution is that it looks at a small square of pixels and can discover spatial information in multiple dimensions at the same time.
This is definitely something I want to read more about, because I currently don't see why convolutional layers would work well on one dimensional sequence data.
Lesson 2: Attention comes in many flavors
In my naive state, I thought attention was like a convolutional layer: it has a specific form and only varies in the size and parameters.
While reading the paper, I learned instead that there is also a method called self-attention and another called multi-head attention. I won't pretend to have understood the details, but in essence multi-head attention seems to be a parallelization of attention, each with its own parameters. This reminds me of using multiple neurons per layer in a fully connected neural network, or creating multiple channels from an image in a convolutional layer. Each of these parallel calculations can focus on a specific aspect of the input - in images, this could be vertical lines and horizontal lines for example.
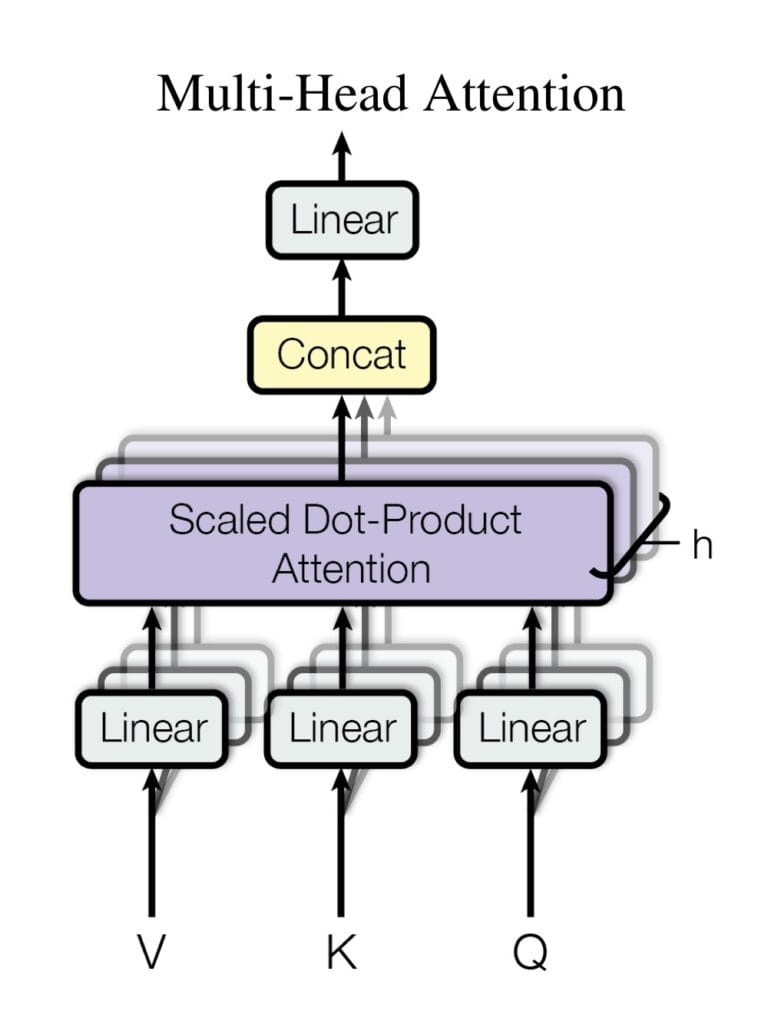
Self-attention, on the other hand, is looking for connections between words in the same sentence, like in the following example between "dog" and "his":

Lesson 3: Attention itself is just a weighted sum
This insight is very similar to the above lesson, because it turns out that even the "simple" attention can differ in the specific attention function used. The two most commonly used attention functions, however, are both surprisingly simple:
- additive attention: which is a feed-forward network with a single hidden layer
- dot-product or multiplicative attention: which consists of computing the dot-product of two vectors, apply a softmax function, and then multiply with another vector
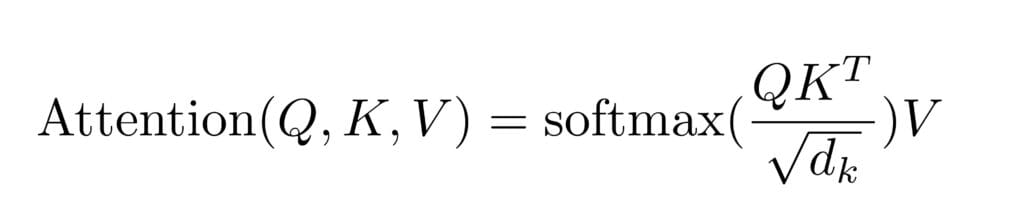
In my opinion, this is extremely "on brand" for neural networks: They perform the most amazing tasks and produce excellent results and after looking under the hood, you discover that they indeed just multiply and add vectors.
As always, there seems to be a method behind the multiplying and adding - and in the case of attention, I haven't understood that yet. I'm also missing some required knowledge about what exactly the "keys", "queries" and "values" are, that are used as input for the attention layer. I suspect these are common terms when talking about sequence transduction models, so I have some catching up to do before coming back to this.
No spam, no sharing to third party. Only you and me.




Member discussion