How to solve Advent of Code 2023 – Day 3 with Python

If you missed any previous days or are looking for another year, click here for all my content about that: Advent of Code, if you want to know why you should participate and try to code the solution for yourself, click here: Advent Of Code 2022 – 7 Reasons why you should participate. If you’re here to see the solution of this year's Day 3, continue reading 😉
GitHub Repository
https://github.com/GalaxyInfernoCodes/Advent_Of_Code_2023
I will upload all of my solutions there in the form of Python notebooks (.ipynb files), but you can copy paste the code into normal .py files, too. I am uploading the examples from the task as ‘example.txt’ files to test my solution. You will have to use your own ‘input.txt’ with your supplied input since everyone gets their own and everyone needs to provide a different solution based on their input.
Day 3 Puzzle
In this blog post I’ll describe the puzzle and solution steps, but if you want to jump ahead to said solution, you can do so here: https://github.com/GalaxyInfernoCodes/Advent_Of_Code_2023/blob/main/Day01_Python/AdventOfCode_Day03_Python.ipynb
Here is the challenge, if you want to read the full puzzle: https://adventofcode.com/2023/day/3
In summary, on day 3 we make it to the gondola lift station. Of course, that lift is also broken and we need to help out. We get an input for a schema that will help us fix it:
467..114..
...*......
..35..633.
......#...
617*......
.....+.58.
..592.....
......755.
...$.*....
.664.598..
This is a grid input, so I parsed it into a numpy (import numpy as np) array. They're a bit easier to work with regarding width and height coordinates than a list of list. Basically I put all the entries into 2D-matrix:
def parse_input(input_file: str) -> np.array:
with open(input_file, "r") as file:
char_array = None
for line in file:
line_chars = list(line.strip())
line_array = np.array(line_chars)
# first line: assignment
if char_array is None:
char_array = line_array
# 2nd to nth line: append to existing 2d-array
else:
char_array = np.vstack((char_array, line_array))
return char_array
Part 1
For the first task, we want to find any number that is adjacent to any symbol (that is not ".").
This gives us two subtasks:
- Finding neighbors of a field and checking if they are a symbol
- Finding (complete) numbers - because numbers can span multiple fields and only one of these fields needs to be adjacent to a neighbor
To find all neighbors of a field I implemented this simple function:
def get_array_neighbors(char_array: np.array, row_index: int, column_index: int):
# build buffer around the array with '.' entries
buffered_array = np.pad(char_array, pad_width=1, mode='constant', constant_values='.')
adjusted_row_index = row_index + 1
adjusted_column_index = column_index + 1
# extract the three-by-three zone of neigbors around the entry
three_by_three_zone = buffered_array[adjusted_row_index - 1:adjusted_row_index + 2, adjusted_column_index - 1:adjusted_column_index + 2]
neighbors = three_by_three_zone.flatten().tolist()
# remove the entry itself
del neighbors[4]
return neighbors
Note: You can of course add every neighbor by hand, but make sure to account for the edge cases. To keep the code a bit shorter I used the numpy array padding function to create a border. Then I can always select a 3x3 field around the entry:
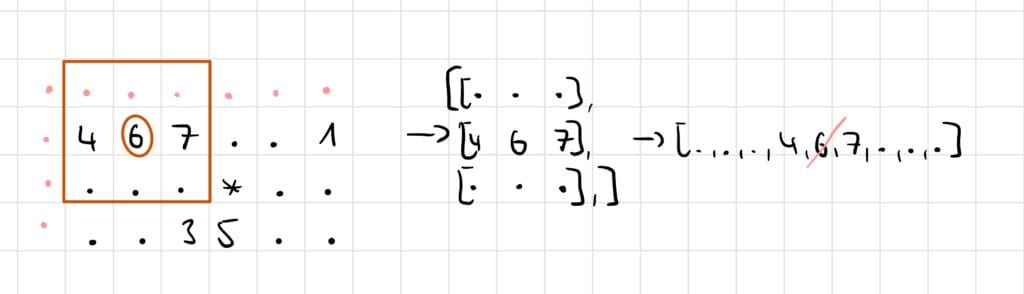
Okay, next we need to find all the numbers and check if they are next to a symbol. For that I iterate through the grid and check each number:
def find_numbers(char_array: np.array):
"""Find the numbers in the array"""
width = len(char_array[0])
numbers = []
for row_index, row in enumerate(char_array):
column_index = 0
while column_index < width:
entry = row[column_index]
if entry.isdigit():
found_numbers, number_valid = check_number(char_array, row_index, column_index)
if number_valid:
combined_found_number = int("".join(found_numbers))
numbers.append(combined_found_number)
column_index += len(found_numbers)
else:
column_index += 1
return numbers
I iterate through the rows, but whenever I find a number I check the whole number (we will see this in the next step), and then skip the whole number in my search. This avoids counting the number twice and ensures I only call check_number with the start-entry of a number.
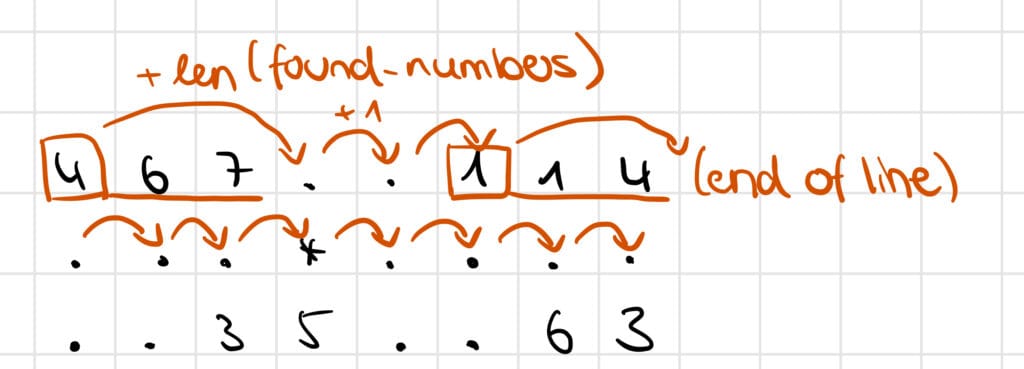
find_numbers methodLet's look at the check_number method. It has two tasks:
- Check if the number is valid by checking each entry of the number for symbols in its neighborhood and returning
Trueif any of them have at least one adjacent symbol. - Combine the whole number by iterating while the current character is a digit (
isdigit())
def check_number(char_array: np.array, row_index: int, column_index: int):
"""Check if the number is valid, i.e. it has a symbol neighbor"""
neighbors = []
numbers = []
while char_array[row_index][column_index].isdigit():
numbers.append(char_array[row_index][column_index])
all_neighbors = get_array_neighbors(char_array, row_index, column_index)
symbol_neighbors = [n for n in all_neighbors if not n.isdigit() and n != '.']
neighbors.extend(symbol_neighbors)
column_index += 1
if column_index >= len(char_array[0]):
break
number_valid = True if len(neighbors) > 0 else False
return numbers, number_valid
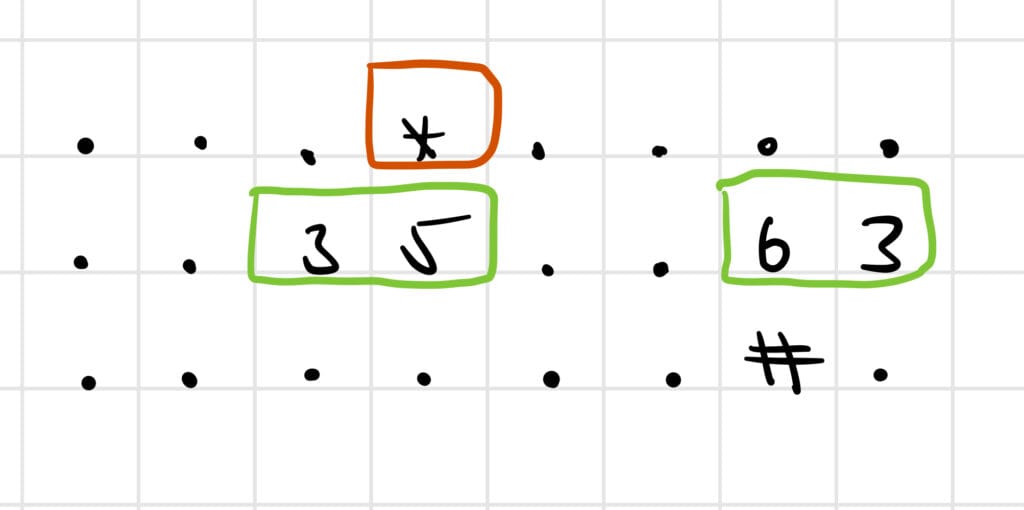
Here's a picture for the number 35, maybe this helps a bit:

For both "3" and "5" we consider the neighborhood (green boxes). In this case the neighborhood contains a "*", so number_valid is True. Side note, the star is counted twice here, but that doesn't affect the result since one symbol is enough to make the number valid.
Let's combine everything - I don't think I need to say much about this:
def solve_part1(input_file: str) -> int:
char_array = parse_input(input_file)
numbers = find_numbers(char_array)
#print("found valid numbers:", numbers)
return sum(numbers)
Part 2
Sooo, here is when we find out that we can't reuse most of my code from Part 1. I focused on finding symbol neighbors of numbers. Now we need to switch things up and count number-neighbors of symbols (specifically the "*" symbol).
The tricky part here is that we can't count the number twice. In the above example, the * only has one number-neighbor, the 35 counts as one neighbor, not two!
So here is my approach for this. I'm not saying it's ideal, it's slightly complicated, but it's the best I could come up with yesterday. We will start with finding all "gears" (the star symbols):
def solve_part2(input_file: str) -> int:
char_array = parse_input(input_file)
gear_coords = np.where(char_array == '*')
gear_ratios = []
for coord in zip(*gear_coords):
print("gear at:", coord)
found_numbers = check_gear(char_array, coord[0], coord[1])
print("found adjacent numbers:", found_numbers)
if len(found_numbers) == 2:
gear_ratios.append(found_numbers[0] * found_numbers[1])
return sum(gear_ratios)
- find the coordinates for the gears with
np.where(I told you numpy can be quite handy for grids) - for each gear call "check_gear" (we'll get to that)
- check how many adjacent numbers were found and use them to calculate the gear ratio, if there are exactly 2 (full) numbers
Okay, but how do we check the gears? Here's the first step:
def check_gear(char_array: np.array, row_index: int, column_index: int) -> List[int]:
upper_numbers = get_number_array_neighbors(char_array, row_index, column_index, location='upper')
left_numbers = get_number_array_neighbors(char_array, row_index, column_index, location='left')
right_numbers = get_number_array_neighbors(char_array, row_index, column_index, location='right')
lower_numbers = get_number_array_neighbors(char_array, row_index, column_index, location='lower')
return upper_numbers + left_numbers + right_numbers + lower_numbers
The idea is to check 4 parts around the gear, which could contain a number. It's probably best if I draw that one too:
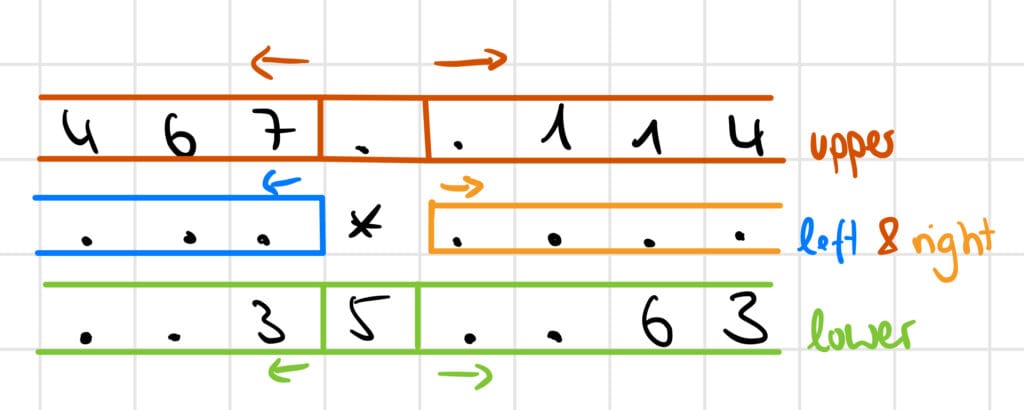
For the check_gear function you only need to understand that all red parts make up what we search in get_number_array_neigbors with location='upper'. Same for 'left' (blue), 'right' (orange) and 'lower' (green). The arrows indicate in which direction we search in these parts.
If it's on the left side we need to search in this direction (reverse) until we run out of numbers in that section. Because the end of that number is adjacent to "*" and we need to find the beginning.
If it's on the right side, we have the start of a potential number adjacent to "*" and we need to find the end. So again, search and combine digits until we find the first non-digit entry.
The only parts left are directly above and below the gear (*). They could potentially hold a number that's connected both on the left and right side. So we insert them between the left and right parts after we searched those and found the ends. This is what happens in this function:
def get_number_array_neighbors(char_array, row_index, column_index, location):
"""Get the row neighbors of the given index entry and expand to left and/or right while there are still numbers"""
if location == 'upper':
if row_index == 0:
return []
number_neighbor_chars = []
# left upper
number_neighbor_chars += get_starting_numbers(char_array[row_index - 1, :column_index], reverse=True)
# upper
middle_entry = ' ' if not char_array[row_index - 1, column_index].isdigit() else char_array[row_index - 1, column_index]
number_neighbor_chars.append(middle_entry)
# right upper
number_neighbor_chars += get_starting_numbers(char_array[row_index - 1][column_index + 1:])
if location == 'lower':
if row_index == len(char_array) - 1:
return []
number_neighbor_chars = []
# left lower
number_neighbor_chars += get_starting_numbers(char_array[row_index + 1, :column_index], reverse=True)
# lower
middle_entry = ' ' if not char_array[row_index + 1, column_index].isdigit() else char_array[row_index + 1, column_index]
number_neighbor_chars.append(middle_entry)
# right lower
number_neighbor_chars += get_starting_numbers(char_array[row_index + 1][column_index + 1:])
if location == 'left':
if column_index == 0:
return []
number_neighbor_chars = get_starting_numbers(char_array[row_index, :column_index], reverse=True)
if location == 'right':
if column_index == len(char_array[0]) - 1:
return []
number_neighbor_chars = get_starting_numbers(char_array[row_index, column_index + 1:])
#print(number_neighbor_chars)
#print('joined and split', "".join(number_neighbor_chars).split(' '))
number_neighbors = [int(number_entry) for number_entry in "".join(number_neighbor_chars).split(' ') if len(number_entry) > 0]
return number_neighbors
Yeah, it's a bit of a mess. But essentially we just slice the char_array (the grid) into the parts I've drawn above. Then we search the resulting slice with get_starting_numbers (seen below). This will only return the row until we run out of numbers:
def get_starting_numbers(one_dim_array: np.array, reverse=False):
"""Get the starting numbers in the array until there is a non-number character-entry"""
index = 0
numbers = []
if reverse:
one_dim_array = one_dim_array[::-1]
while index < len(one_dim_array) and one_dim_array[index].isdigit():
numbers.append(one_dim_array[index])
index += 1
if reverse:
numbers = numbers[::-1]
return numbers
Note: We pass reverse=True for the left parts, so they are searched back-to-front. We reverse again at the end so it's in the original orientation again. This ensures that I can I use the same search-function for both left and right parts.
At the end of the check_gear (seen above) function the resulting found numbers are parsed:
number_neighbors = [int(number_entry) for number_entry in "".join(number_neighbor_chars).split(' ') if len(number_entry) > 0]
Split the found and cut-off areas ("".join(number_neighbor_chars) to create a full string again) around the gear at the whitespace (I replaced . with ' ' somewhere). Then convert each number with casting (calling int(...) is called type-casting).
Note: The len(number_entry) > 0 is needed because .split(' ') returns some empty strings ('').
Aaand that's it. Yeah.
Conclusion
If you struggled with this, that's okay. There's probably many ways to approach all the different parts to check for numbers and symbols. For things like this, it's always best to find a way that makes the most sense for your brain. Nevertheless, maybe my way of thinking about the different neighbor-sections gave you an idea if you're stuck. Consider step-by-step on paper how you would approach this. Which parts are needed? When can you stop searching? etc.
I did find this puzzle kind of tricky, but it was even trickier trying to describe my though process on here 😅 I hope my drawings made some sort of sense. And remember, you can skip days and return later to them. Day 4 at least doesn't have any more grids...
No spam, no sharing to third party. Only you and me.



Member discussion