Intro to Scene Text Recognition - Guide to Image-to-Text Conversion

Recognizing text in a photo - something we're quite good at, but neural networks struggle quite a bit with it. While OCR (Optical Character Recognition) (OCR Wikipedia) is a fairly well-known concept, the very similar Scene Text Recognition (STR) problem is not talked about as much.
It’s always easier to show than to explain, so here are some examples where you would prefer models trained for STR:

The challenge behind the task: Combining multiple areas
I found working with these models and looking into their techniques quite interesting. Mainly because they combine multiple fields:
- 🔎 Finding text in a photo, similar to localizing an object, but the text can have very varied lengths and shapes.
- 🔄 Parsing each character or symbol into a feature vector, similar to object detection.
- 🗣️ Applying NLP techniques to increase the likelihood that the resulting text actually makes sense (e.g., full words and sentences)
Common model components
Often, many of the above mentioned parts are actually combined into one end-to-end neural network, with convolutions, RNNs (or other sequence models), and language models trained through one loss function.
If you're interested in learning more details, I can recommend the paper "An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition” (Baoguang Shi et al., 2015) which presents one of the earlier model versions for this task and goes into all of the components.
Benchmark Datasets for the Scene Text Recognition Task
On Paperswithcode.com you can find a list of relevant datasets that have been used often to measure the performance of STR models in research papers with the goal to compare against previous state of the art model:
Scene Text Recognition Benchmark Datasets
For example, in the PARSeq model (SOTA 2022, see below) paper, the authors state they used the typical 6 datasets for evaluation:
- IIIT 5k-word (IIIT5k)
- CUTE80 (CUTE)
- Street View Text (SVT),
- SVT-Perspective (SVTP),
- ICDAR 2013 (IC13), and
- ICDAR 2015 (IC15)
Most of these show a very similar image over time. Let’s look at IDCAR2015 as an example:
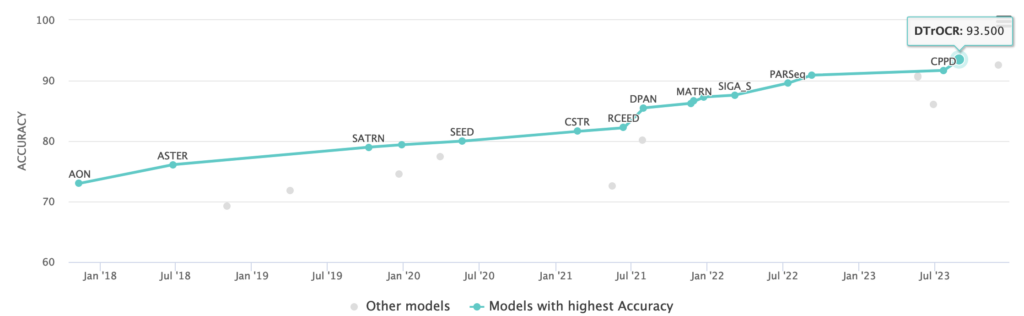
You can see that in recent years, progress has been slow. That’s because models have become quite good, so there hasn’t been much need for further innovation - in fact most high end smartphones are capable of selecting text in photos now in milliseconds.
However, the benchmark datasets mentioned above are also quite small - in total only 7,600 images. That’s a common problem with benchmarks: They are used again and again to allow for comparison between models but over time the models outgrow them. Models achieved over 90% accuracy in recent years - but does this mean they mastered the task of Scene Text Recognition or did they just excel and the few chosen examples?
More recent datasets - with larger sample sizes - have now been created. Like COCO-Text with 9.8k sample images, ArT (35k samples) and Uber-Text (80k samples).
An easy starting model: EasyOCR
If you want to try this out yourself and play around with it first, I would recommend trying the EasyOCR library available on GitHub: https://github.com/JaidedAI/EasyOCR
This library comes with an easy to use interface and has pretrained models for various languages:
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
result = reader.readtext('chinese.jpg')
You can change between a few supported models and it even includes some lightweight ones that
A word of warning: Just don't try to run it with the Mac MPS acceleration or are cautious at least… Sadly, when I last checked in September 2023, the library didn't properly support it and some methods stopped returning results when you switched from CUDA to MPS.
State-of-the-Art models: PARSeq and DTrOCR
PARSeq - SOTA on Scene Text Recognition in 2022
If you are looking for a model to immediately try out on a more serious task, a good starting point I can recommend from experience is the PARSeq model. It was State-of-the-Art, meaning it was first on most benchmarks, in 2022. However, in the time since it as only been superseded by a few percent points, so it remains relevant in 2024 as well.
PARSeq Code: https://github.com/baudm/parseq
The GitHub is well documented and well-kept, which is not the case for every research model. Because of this, we had little trouble accessing the pretrained models and getting them to run on our machines. There even was some code and tips provided for fine-tuning on our specific user data. This fine-tuning on your data is something you might want to try out if the pretrained model doesn't give you the desired results right out of the box.
PARSeq Research Paper: https://arxiv.org/abs/2207.06966
DTrOCR - SOTA on Scene Text Recognition in 2024
DTrOCR: I don't have personal experience with this, but right now in 2024, this seems to be the top performing model on standard benchmarks. Overall, the key change to PARSeq in model architecture seems to be that DTrOCR doesn't use a vision transformer encoder, and instead just chops the image into a series of patches that undergo what they call "Patch Embedding". How exactly the implementation differs from PARSeq is hard to see however, as they do not seem to have made the code or even the specific architecture public. It seems to me that the inclusion of decoder-only transformers like GPT-2 in the architecture would possibly make it a stronger candidate for longer texts, but probably not bring much improvement to tasks like reading IDs in the form of "AD 483023".
DTrOCR Code: If you find it, please let me know... I guess you could try rebuilding it from the hints in the paper, however you wouldn't have a pretrained model and would need to do your own training.
Sources & Further Reading
Models:
- PARSeq: Bautista, D. and Atienza, R., October. Scene text recognition with permuted autoregressive sequence models. In European Conference on Computer Vision (pp. 178-196). Cham: Springer Nature Switzerland. (2022)
- CRNN: Shi, B., Bai, X. and Yao, C., An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), pp. 2298-2304. (2016)
- DTrOCR: Fujitake, M., Dtrocr: Decoder-only transformer for optical character recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 8025-8035) (2024)
Benchmark papers:
- IIIT 5k-word (IIIT5k): Mishra, A., Alahari, K., Jawahar, C.: Scene text recognition using higher order language priors. In: BMVC-British Machine Vision Conference. BMVA (2012)
- CUTE80 (CUTE): Risnumawan, A., Shivakumara, P., Chan, C.S., Tan, C.L.: A robust arbitrary text detection system for natural scene images. Expert Systems with Applications 41(18), 8027–8048 (2014)
- Street View Text (SVT): Wang, K., Babenko, B., Belongie, S.: End-to-end scene text recognition. In: 2011 International Conference on Computer Vision. pp. 1457–1464. IEEE (2011)
- SVT-Perspective (SVTP): Phan, T.Q., Shivakumara, P., Tian, S., Tan, C.L.: Recognizing text with perspective distortion in natural scenes. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 569–576 (2013)
- ICDAR 2013 (IC13): Karatzas, D., Shafait, F., Uchida, S., Iwamura, M., i Bigorda, L.G., Mestre, S.R., Mas, J., Mota, D.F., Almazan, J.A., De Las Heras, L.P.: Icdar 2013 robust reading competition. In: 2013 12th International Conference on Document Analysis and Recognition. pp. 1484–1493. IEEE (2013)
- ICDAR 2015 (IC15): Karatzas, D., Gomez-Bigorda, L., Nicolaou, A., Ghosh, S., Bagdanov, A., Iwamura, M., Matas, J., Neumann, L., Chandrasekhar, V.R., Lu, S., et al.: Icdar 2015 competition on robust reading. In: 2015 13th International Conference on Document Analysis and Recognition (ICDAR). pp. 1156–1160. IEEE (2015)
No spam, no sharing to third party. Only you and me.




Member discussion